��SQL Server�Ќ��F(xi��n)���·�������Ľ�Q����_Mssql��(sh��)����̳�
���]��Sql�W����һ�졪��SQL �����}(����/sql�Z��)����Madrid��ӆ�Δ�(sh��)����3�����M��,ᘌ��@��Ҫ����������:�������}�����Լ�sql�Z��Č��������dȤ�����ѿ��ԅ����¹���ϣ�����Ԏ�������
�_ʼ
�@��ȥ��Ć��}�ˣ������������]���ĕr��Űl(f��)�F(xi��n)�@�����}�����X�����˼�ģ���ӛ�����
�ڱ�RelationGraph�У��������ֶΣ�ID,Node,RelatedNode��,����Node��RelatedNode�ɂ��ֶ������ɂ���(ji��)�c���B���Pϵ���F(xi��n)��Ҫ���ҳ��Ĺ�(ji��)�c"p"����(ji��)�c"j"�����·���������^�Ĺ�(ji��)�c���٣���
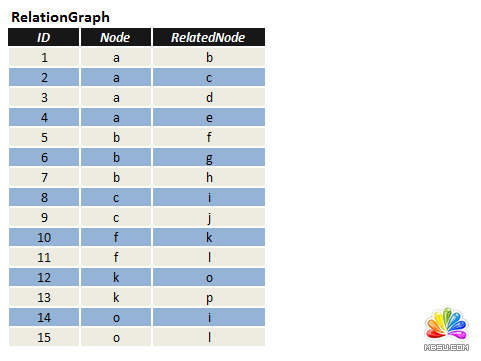
�D1.
������
���܉���õ�������RelationGraph���ֶ�Node�� RelatedNode���Pϵ�������@������ʹ��һ���D��������
��D2.

�D2.
�ڈD2���������Ŀ���������(ji��)�cֱ��������B��Ҳ��������Ŀ�����(ji��)�c"p"����(ji��)�c"j"�ĵĎN����·����

��������Կ�����2�N����·�������^�Ĺ�(ji��)�c���١�
���˽�Q�_ʼ�Ć��}���҅����˃ɷN������
��1�����ǣ�
������Դ���·���㷨��Dijkstra(�Ͻ�˹����)�㷨����Ҫ���c������ʼ�c����������ӌӔUչ��ֱ���Uչ���K�c��ֹ��

�D3.
��2�����ǣ�
ᘌ���1�N�����ĸ��M�����Dz��ö�Դ�c�������@������Թ�(ji��)�c"p"��(ji��)�c"j"����������ӔUչ��ֱ���ɈA�����c����D4. ��
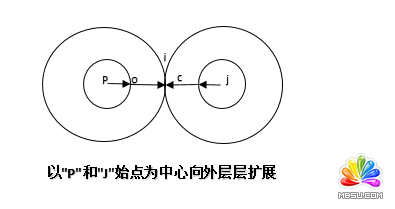
�D4.
���F(xi��n)��
�ڽ������Ҿ�������SQL Server�У���Ό��F(xi��n)����Ȼ���@����õ�ǰ���f�ĵ�2�N��������"P"��"J"��ʼ�c��������ӌӔUչ��
�@���ṩ�б�RelactionGraph��create& Insert��(sh��)�����_����
use TestDB
go
if object_id('RelactionGraph') Is not null drop table RelactionGraph
create table RelactionGraph(ID int identity,Item nvarchar(50),RelactionItem nvarchar(20),constraint PK_RelactionGraph primary key(ID))
go
create nonclustered index IX_RelactionGraph_Item on RelactionGraph(Item) include(RelactionItem)
create nonclustered index IX_RelactionGraph_RelactionItem on RelactionGraph(RelactionItem) include(Item)
go
insert into RelactionGraph (Item, RelactionItem ) values
('a','b'),('a','c'),('a','d'),('a','e'),
('b','f'),('b','g'),('b','h'),
('c','i'),('c','j'),
('f','k'),('f','l'),
('k','o'),('k','p'),
('o','i'),('o','l')
go
����һ���惦�^��up_GetPath
use TestDB
go
--Procedure:
if object_id('up_GetPath') Is not null
Drop proc up_GetPath
go
create proc up_GetPath
(
@Node nvarchar(50),
@RelatedNode nvarchar(50)
)
As
set nocount on
declare
@level smallint =1, --��ǰ���������
@MaxLevel smallint=100, --�����������
@Node_WhileFlag bit=1, --��@Node���������M�������r�������ܷ�ѭ�h(hu��n)�����Ę�ӛ
@RelatedNode_WhileFlag bit=1 --��@RelatedNode���������M�������r�������ܷ�ѭ�h(hu��n)�����Ę�ӛ
--���ֱ���ҵ��ɂ�Node����ֱ���Pϵ��ֱ�ӷ���
if Exists(select 1 from RelationGraph where (Node=@Node And RelatedNode=@RelatedNode) or (Node=@RelatedNode And RelatedNode=@Node) ) or @Node=@RelatedNode
begin
select convert(nvarchar(2000),@Node + ' --> '+ @RelatedNode) As RelationGraphPath,convert(smallint,0) As StopCount
return
end
--
if object_id('tempdb..#1') Is not null Drop Table #1 --�R�r��#1���惦������@Node������������Uչ�ĸ���(ji��)�c��(sh��)��
if object_id('tempdb..#2') Is not null Drop Table #2 --�R�r��#2���惦������@RelatedNode������������Uչ�ĸ���(ji��)�c��(sh��)��
create table #1(
Node nvarchar(50),--����Դ�c
RelatedNode nvarchar(50), --����Ŀ��
Level smallint --���
)
create table #2(Node nvarchar(50),RelatedNode nvarchar(50),Level smallint)
insert into #1 ( Node, RelatedNode, Level )
select Node, RelatedNode, @level from RelationGraph a where a.Node =@Node union --������@Node����Դ��ԃ
select RelatedNode, Node, @level from RelationGraph a where a.RelatedNode = @Node --������@Node����Ŀ���M�в�ԃ
set @Node_WhileFlag=sign(@@rowcount)
insert into #2 ( Node, RelatedNode, Level )
select Node, RelatedNode, @level from RelationGraph a where a.Node =@RelatedNode union --������@RelatedNode����Դ��ԃ
select RelatedNode, Node, @level from RelationGraph a where a.RelatedNode = @RelatedNode --������@RelatedNode����Ŀ���M�в�ԃ
set @RelatedNode_WhileFlag=sign(@@rowcount)
--����ڱ�RelationGraph���Ҳ���@Node �� @RelatedNode ��(sh��)������ֱ�����^�����While�^��
if not exists(select 1 from #1) or not exists(select 1 from #2)
begin
goto While_Out
end
while not exists(select 1 from #1 a inner join #2 b on b.RelatedNode=a.RelatedNode) --�Д��Ƿ���F(xi��n)���c
and (@Node_WhileFlag|@RelatedNode_WhileFlag)>0 --�Д��Ƿ�������
And @level<@MaxLevel --�������
begin
if @Node_WhileFlag >0
begin
insert into #1 ( Node, RelatedNode, Level )
--����
select a.Node,a.RelatedNode,@level+1
From RelationGraph a
where exists(select 1 from #1 where RelatedNode=a.Node And Level=@level) And
Not exists(select 1 from #1 where Node=a.Node)
union
--����
select a.RelatedNode,a.Node,@level+1
From RelationGraph a
where exists(select 1 from #1 where RelatedNode=a.RelatedNode And Level=@level) And
Not exists(select 1 from #1 where Node=a.RelatedNode)
set @Node_WhileFlag=sign(@@rowcount)
end
if @RelatedNode_WhileFlag >0
begin
insert into #2 ( Node, RelatedNode, Level )
--����
select a.Node,a.RelatedNode,@level+1
From RelationGraph a
where exists(select 1 from #2 where RelatedNode=a.Node And Level=@level) And
Not exists(select 1 from #2 where Node=a.Node)
union
--����
select a.RelatedNode,a.Node,@level+1
From RelationGraph a
where exists(select 1 from #2 where RelatedNode=a.RelatedNode And Level=@level) And
Not exists(select 1 from #2 where Node=a.RelatedNode)
set @RelatedNode_WhileFlag=sign(@@rowcount)
end
select @level+=1
end
While_Out:
--�����ǘ��췵�صĽY��·��
if object_id('tempdb..#Path1') Is not null Drop Table #Path1
if object_id('tempdb..#Path2') Is not null Drop Table #Path2
;with cte_path1 As
(
select a.Node,a.RelatedNode,Level,convert(nvarchar(2000),a.Node+' -> '+a.RelatedNode) As RelationGraphPath,Convert(smallint,1) As PathLevel From #1 a where exists(select 1 from #2 where RelatedNode=a.RelatedNode)
union all
select b.Node,a.RelatedNode,b.Level,convert(nvarchar(2000),b.Node+' -> '+a.RelationGraphPath) As RelationGraphPath ,Convert(smallint,a.PathLevel+1) As PathLevel
from cte_path1 a
inner join #1 b on b.RelatedNode=a.Node
and b.Level=a.Level-1
)
select * Into #Path1 from cte_path1
;with cte_path2 As
(
select a.Node,a.RelatedNode,Level,convert(nvarchar(2000),a.Node) As RelationGraphPath,Convert(smallint,1) As PathLevel From #2 a where exists(select 1 from #1 where RelatedNode=a.RelatedNode)
union all
select b.Node,a.RelatedNode,b.Level,convert(nvarchar(2000),a.RelationGraphPath+' -> '+b.Node) As RelationGraphPath ,Convert(smallint,a.PathLevel+1)
from cte_path2 a
inner join #2 b on b.RelatedNode=a.Node
and b.Level=a.Level-1
)
select * Into #Path2 from cte_path2
;with cte_result As
(
select a.RelationGraphPath+' -> '+b.RelationGraphPath As RelationGraphPath,a.PathLevel+b.PathLevel -1 As StopCount,rank() over(order by a.PathLevel+b.PathLevel) As Result_row
From #Path1 a
inner join #Path2 b on b.RelatedNode=a.RelatedNode
and b.Level=1
where a.Level=1
)
select distinct RelationGraphPath,StopCount From cte_result where Result_row=1
go
����Ĵ惦�^�̣���Ҫ�֞�ɴ֣���1�����nj��F(xi��n)�����������2�����F(xi��n)��Θ��췵�ؽY�������е�1���ֵĴ��a����ǰ��ķ���2��ͨ�^@Node �� @RelatedNode �ɂ���(ji��)�c�����������ÿ���������صĹ�(ji��)�c���������R�r��#1��#2�����Д��R�r��#1��#2�Л]�г��F(xi��n)���c��������F(xi��n)���f�����ҵ���̵�·�������^�(ji��)�c��(sh��)���٣�����t���^�m(x��)ѭ�h(hu��n)������ֱ��ѭ�h(hu��n)������������ȣ�@MaxLevel smallint=100�����ҵ����c��Ҫ�ǵ�100�Ӷ��]���������c�����ŗ��������@��ʹ�������������@MaxLevel��Ŀ���ǿ������ڔ�(sh��)��������ܕ��������ܲ������@�(sh��)�����c�������ܳɷ��ȡ����a��߀�f��һ������ͷ�����������Ҫ������Node �� RelatedNode���f�����������酢�Ռ����M����������ʹ�á�
�����Ǵ惦�^�̵Ĉ�(zh��)�У�
use TestDB
go
exec dbo.up_GetPath
@Node = 'p',
@RelatedNode = 'j'
go

����Ը�����Ҫ�����x��@Node �� @RelatedNode��ͬ��ֵ��
��չ��
ǰ������ӣ��ɔUչ�����еĹ���·�����ṩ�ɂ�վ�c���������^�@�ɂ�վ�c����վ�c����·�������ԔUչ����^(q��)�����H�Pϵ����������һ�����c��һ�������J�R����ô����ֱ��Ҫ���^���ق��˲ſ��ԡ��������c��ֱ����ֱ�ӵ����ѡ��H���P(li��n)��߀����ͨ�^���c�����P(li��n)�ҵ����c���P(li��n)����ׂ�����ͨ�^����һ��������ô���f���@�ׂ��˿���ͨ�^ijһ�����������б����ҵ��������ڹ�ͬ����������P(li��n)���@�������ɂ����J�R·���ṩ�������@���}���ܕ��dz�����s���������@�ӵĔUչ��
�Y��
�@��ֻ���҃ɂ���(ji��)�c������·���У���(ji��)�c��(sh��)���ٵ�·�����ڌ��H�đ����У����ܕ��������@������s����r���������ĭh(hu��n)����������ܕ������L�ȣ��r�g���(ji��)�c�����������һЩ��Ϣ���oՓ��Σ�һ�㶼Ҫ����һЩԭ�����㷨�팍�F(xi��n)��
������Sql�W�������졪��SQL �P��with ties��Bwith tiesһ���Ǻ�Top , order by��Y��ʹ�õ�,����ԃ�����һ�l��(sh��)���~��ķ���ֵ�����팢����Ԕ����B�£����dȤ�ĸ�λ���ԅ����¹�
- sql �Z�侚���c��
- ����C++ string.find()����(sh��)���÷����Y
- SQL Server�Єh���؏͔�(sh��)���Ďׂ�����
- sql�h���؏͔�(sh��)����Ԕ������
- SQL SERVER 2000���b�̳̈D��Ԕ��
- ʹ��sql server management studio 2008 �o���鿴��(sh��)����,��ʾ �o����ԓՈ��z����(sh��)�� �e�`916��Q����
- SQLServer��־����Z��(sql2000,sql2005,sql2008)
- Sql Server 2008��ȫж�d����(�����汾���)
- sql server 2008 �����S������ģ��������ĸ���Ҫ��h��������(chu��ng)�����±�
- SQL Server 2008 ��Մh����־�ļ�(˲�g��־׃��M)
- Win7ϵ�y(t��ng)���bMySQL5.5.21�D��̳�
- ��DataTable����惦�^�̅���(sh��)���÷�����Ԕ��
Mssql��(sh��)����̳�Rssӆ����̳̽�����
Mssql��(sh��)����̳����]
- SQL2005����ROW_NUMBER() OVER���F(xi��n)��퓹���
- sql server���Д�(sh��)��ƴ�ӵČ�������
- SQL 2005 ERROR:3145 ��Q�k��(��ݼ��еĔ�(sh��)�������c�F(xi��n)�еĔ�(sh��)���첻ͬ)
- ֔ӛSQL Server���������������F��
- ������Ч��SQLSERVER��퓲�ԃ(��N����)
- ���ʹ��SQL Server�����\��CmdExec����
- sql server 2008 �����S������ģ��������ĸ���Ҫ��h��������(chu��ng)�����±�
- ͨ�^SQL�L�Ɨ��x���ǵČ��F(xi��n)������B
- SQLServer��־����Z��(sql2000,sql2005,sql2008)
- SELECT �xֵ�cORDER BY�_ͻ�Ć��}
����Ҳϲ�g���@Щ
- mysql���b����F(xi��n)�y�a�O�Þ�utf8�ɽ�Q
- MySQL����O���ܴa
- �W�ģ��MySQL���F(xi��n)Can't create/write to file 'C:\Windows\TEMP\#sql_990_0.MYI��Q�k��
- MySQL�Pӛ֮��(sh��)�W����(sh��)Ԕ��
- SQL�Z����Q�ֶ��еēQ�з�����܇��
- ����mysql�ա�ҕ�D���惦�^�̡��|�l(f��)���đ��÷���
- ����mysql "ON DUPLICATE KEY UPDATE" �Z���ķ���
- MySQL���������
- ����text�ֶΕr���F(xi��n)Row size too large���e������ʩ
- �h���B��mysql��(sh��)����ע���cӛ�
- ���P朽ӣ�
- �̳��f����
Mssql��(sh��)����̳�-��SQL Server�Ќ��F(xi��n)���·�������Ľ�Q����
 ��
��